This blog is part of a series of blogs aimed at sharing our experiences with DFID’s macro evaluations. Background information about the macro evaluations as well as details on the methodology applied can be found on the project page.
In April 2016, we presented methodological lessons from our macro evaluation of DFID’s Empowerment and Accountability policy frame at the UK Evaluation Society (UKES) annual conference and at a seminar for the Centre for Development Impact (CDI). As Itad has been conducting this evaluation since 2014, we thought it was time to share some of our learning. Both presentations led to engaging discussions with the audience, and there was a lot of useful feedback we’ll chew over to refine our evaluation approach.
So what did we present? The UKES conference had a theme around ‘unpacking complexity’, so we tried to focus on lessons about evaluating complex change processes. Our evaluation methodology was probably more complicated than complex, but our evaluand certainly was complex – it consisted of the complex change processes observed in 180 DFID projects focussed on social accountability, all with different budgets and timeframes, in different countries and regions, and using different modalities and approaches. From this portfolio we tried to generate learning around ‘what works, for whom, in what contexts and why’.
Our methodology
Our evaluation methodology was designed to capture the breadth of this large and diverse portfolio without losing the depth of analysis of complex change processes. We used a theory-based approach to understanding causality that rigorously combined Qualitative Comparative Analysis (QCA) with narrative analysis. There were four key elements to this approach as illustrated in the diagram below:
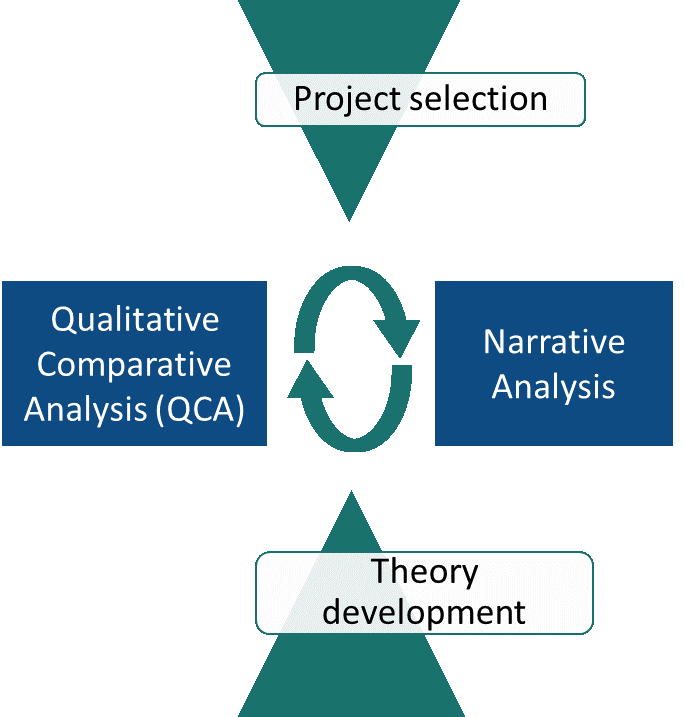
- First, we engaged in a lengthy and systematic process to select a sample of 50 projects for QCA with the best data quality. We also tested the representativeness of this sample. We further selected 13 projects for narrative analysis, sampling ‘true positive’ and ‘false positive’ cases selected via the Hamming measure of distance.
- Second, we developed testable hypotheses based on theory. Inspired by realist thinking, these hypotheses were expressed as combinations of ‘contexts’, ‘mechanisms’ and ‘outcomes’. They covered recent debates such as Jonathan Fox’s writing on ‘low accountability traps’.
- Next, we subjected these hypotheses to testing via QCA. This allowed us to systematically compare 50 projects and identify patterns of association confirming or rejecting our hypotheses. To do this, we extracted data for all our ‘contexts’, ‘mechanisms’ and ‘outcomes’ from project documentation and provided a binary score for each of them.
- Finally, we engaged in a qualitative in-depth comparative analysis of 13 projects to interpret and explain the patterns identified through QCA. We focussed on identifying explanatory models that explain differences between ‘true positive’ cases and ‘false positive’ cases (i.e. cases with the same configurations of mechanisms/contexts but a different outcome). We also conducted Key Informant Interviews to supplement our secondary evidence for each case study.
Challenges
We encountered three key challenges throughout this process:
- The challenge of data quality
As a macro evaluation, the evaluation was primarily dependent on secondary data, i.e. project documentation. The quality of this documentation varied and was often insufficient for our analysis. Evaluations were rare among the projects analysed, and we often had to resort to Annual Reviews and other project reports.
Despite selecting the projects with the best available data, and filling data gaps through Key Informant Interviews, our QCA dataset had 104 out of 1,200 data points missing. This required the manual construction of different sub-datasets for each hypothesis and limited our ability to perform more inductive analysis using QCA. When we conducted the narrative analysis, the variation in data quality also meant that our evidence base was mixed and stronger for some hypotheses than for others.
- The challenge of unpacking ‘context’
Inspired by realist thinking, one of our objectives was to understand the role of ‘context’. We hoped to generate findings such as ‘if mechanism X is implemented in context Y, outcome Z is achieved’. This is why we included context factors in our hypotheses and tried to assess their role.
However, we struggled to find interesting associations involving project contexts. We scored contexts using global indices such as the CIVICUS civil society index, informed by O’Meally’s social accountability context domains. This allowed for some comparability and relative objectivity, but meant that our contexts were too broad to produce meaningful learning. On the other hand, when conducting the narrative analysis, we found a large number of context factors that were important for success. However, these were very specific to each case study and it was difficult to generalise across cases.
In short, we found ourselves a bit stuck between too much specificity and too much abstraction, and weren’t able to generate a lot of useful evidence on ‘what works in what contexts’.
- The challenge of sequencing and iteration
Our methodology was based on the idea of iterating between our two methods (QCA and narrative analysis), fine-tuning learning generated by one method with the other and then iterating again to further specify our findings. In reality, however, this was difficult due to the sequential nature of the process and the long timeline required.
For instance, we had to finalise our hypotheses before we could start extracting data and coding contexts, mechanisms, and outcomes. But data extraction threw up additional factors and hypotheses to be tested, which would have required another round of data extraction/coding – for which we simply didn’t have the time. Similarly, we had to finalise the QCA before we could select the case studies for narrative analysis. The narrative analysis helped fill gaps in the initial dataset, resulting in a slightly different final dataset (for which we did re-do the QCA). The additions to the dataset may also have affected the case study selection in some cases (through changes to the Hamming distance of similarity), which would have required another round of Hamming distance calculations and possibly resulted in a slightly different case study selection. Again, there was no time for such iteration.
Conclusion
Overall, combining QCA with narrative analysis proved useful. The narrative analysis helped interpret and explain QCA findings, while QCA provided numerical evidence based on a relatively large number of cases to back up our findings.
For instance, we were able to confirm Jonathan Fox’s thinking about ‘low accountability traps’ and found that it was challenging for social accountability initiatives to achieve change beyond the local level. We were also able to further qualify this finding, by adding that social accountability initiatives that fed evidence upwards to directly support policy change managed to increase the likelihood of national-level success from 0% to 29%. Our findings also include further in-depth explanations of how and under which conditions this process works.
